Les Deeptech au secours du Contrôle de Gestion
Publié par Vladimir Lernould, directeur de missions, Nell'Advisory (Nell'Armonia) le - mis à jour à
Les deeptech, Machine Learning, IA, RPA, représentent un levier majeur de compétitivité et de revenu dans les entreprises. Mais leur application s'avère être un véritable défi. Comment aborder ce changement de paradigme ?
Seule une entreprise française sur cinq a pris la mesure de cette nouvelle révolution technologique, selon l'étude BCG 2018 (1).
Un rapport du Capgemini Research Institute2 révèle que le secteur des services financiers pourrait espérer un gain de 512 milliards de dollars de revenus supplémentaires d'ici 2020 grâce à " l'automatisation intelligente ". Pour atteindre cet objectif, les entreprises du secteur devront combiner l'automatisation des processus par la robotique (RPA) avec l'intelligence artificielle et de nouveaux leviers d'optimisation des processus.
Pourtant, l'adoption de l'automatisation intelligente peine à prendre de la vitesse. Seulement 10% des entreprises interrogées indiquent l'avoir déployée à grande échelle (2).
Automatiser les tâches récurrentes à faible valeur ajoutée
La fonction Finance et plus particulièrement le Contrôle de Gestion font face à des problèmes récurrents dans des processus tels que le suivi budgétaire ou encore la clôture comptable. Ces difficultés pouvant se traduire dans le système d'information par des erreurs d'imputations comptables ou analytiques. L'automatisation d'une grande partie de ces processus stables de l'entreprise pourrait laisser d'une part une place plus importante à l'analyse, et d'autre part accélérer et améliorer la qualité de leur exécution.
Pour comprendre comment automatiser les tâches récurrentes à faible valeur ajoutée, intéressons-nous rapidement aux technologies disponibles.
{kind=link}
Figure1 - Imbrication des technologies
Le Deep Learning (DL) s'appuie sur des réseaux de neurones virtuels pour résoudre des problèmes complexes. Le DL est un sous-ensemble du Machine Learning (ML) qui repose sur des algorithmes avec une approche statistique, et sur de grands volumes de données.
La Robotic Process Automation (RPA) permet de créer des robots reproduisant des tâches humaines à faible valeur ajoutée au travers d'outils modernes. Ces outils apportent l'aisance à la création des robots et à la remontée d'informations en s'inscrivant dans des workflows idoines.
L'Intelligence Artificielle (IA) englobe ces technologies et vise à faire produire des résultats " intelligents " aux algorithmes.
{kind=link}
Le contrôle de gestion fait face à de nombreux problèmes récurrents, malgré la présence d'outils décisionnels dédiés (systèmes de gestion, de construction et d'élaboration budgétaire, de reporting). Certaines tâches restent entièrement manuelles et à la discrétion des contrôleurs. Lors de la clôture du réalisé, il est courant de constater des erreurs d'imputation, ces erreurs devant être analysées puis soit expliquées, soit corrigées.
Dans l'absolu, tout problème d'ordre comptable pourrait être identifié automatiquement à l'aide d'un algorithme de recherche. La difficulté réside dans l'intelligence autour du " quoi " chercher.
Un processus d'identification infaillible
La phase fondamentale d'identification des erreurs pourrait être automatisée en grande partie, en utilisant le Deep Learning. En effet, en faisant apprendre au " système " les motifs et moyens permettant de détecter des erreurs par l'oeil humain, il serait possible de faire reproduire à ce " système " des routines de contrôle lors de la remontée du réalisé en période de clôture, voire de manière anticipée.
Dans un second temps, l'automatisation et la collecte de ces erreurs, voire de leur correction, seraient traitées à l'aide de la RPA. Nous pourrions ainsi imaginer que chaque contrôleur reçoive chaque matin une présélection d'erreurs liées à son périmètre, triées par ordre d'importance et avec déjà, pour certaines, des propositions de résolution basées sur des clôtures précédentes.
Concernant les dépenses, lorsqu'une écriture manque, un "robot chercheur" pourrait répondre "Je n'ai pas trouvé d'imputation" telle qu'attendue. Si une écriture est en trop, le robot pourrait identifier la ligne qui ne devrait pas être affectée sur ce croisement.
Une ultime phase serait d'ajouter un chatbot pour rendre interactif l'échange "homme - machine" et permettre un requêtage en langage naturel sur la base de connaissance des erreurs de clôture déjà identifiées et traitées. La mise en place d'un chatbot sera vecteur d'accélération dans le processus de compréhension de l'anomalie en rendant possible l'usage de requêtes interactives en langage naturel sur les systèmes comptables sous-jacents et proposera également de répondre par exemple à la question suivante : " Pour cette erreur d'imputation, quelles étaient les écritures des deux mois précédents ? ".
Les étapes clés de la mise en oeuvre
Maintenant que nous avons identifié les composantes principales de ce processus, regardons à présent plus en détail la mise en oeuvre de l'automatisation des tâches d'identification et de correction des anomalies.
Rappelons que dans cet exemple une anomalie se traduit par une écriture ou imputation inattendue, cette écriture peut être détaillée sur plusieurs axes analytiques ou organisationnels (tels que le centre d'imputation ou de responsabilité budgétaire, un pays, un segment de produit, etc.).
{kind=link}
Figure2 - Imbrication des technologies
{kind=link}
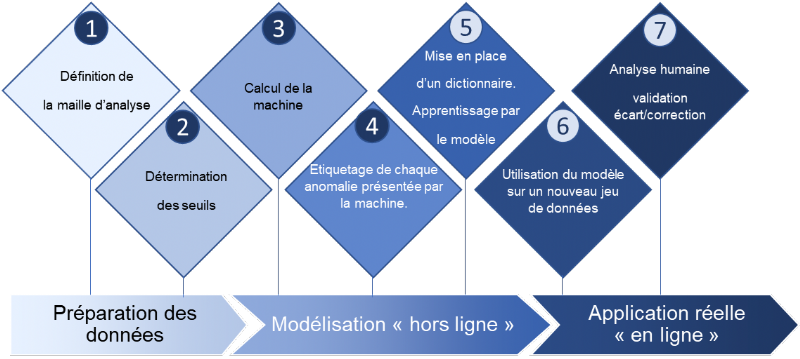
La première étape consiste donc à définir la maille d'analyse (c'est-à-dire les niveaux de croisements ou combinaisons pour lesquels ces anomalies devront être détectées).
Lors de la seconde étape, les valeurs pour chaque combinaison sont extraites pour permettre de déterminer les seuils (peut-être par exemple un seuil de valeur fixe en devise). Chaque seuil identifie une catégorie de montant qui servira ensuite à déterminer le niveau de criticité de l'anomalie.
La troisième étape correspond au calcul de la machine, celle-ci va présenter les anomalies " candidates " devant être analysées par le contrôleur de gestion sur la base des seuils préalablement établis.
La quatrième étape, la plus importante, vise à étiqueter chaque anomalie candidate présentée par la machine. Les étiquettes peuvent être multiples et correspondre à des cas fonctionnels bien précis. C'est ici que le contrôleur va documenter l'ensemble des anomalies connues.
Lors de la cinquième étape, le système va apprendre en s'appuyant sur le dictionnaire renseigné par le contrôleur en étape quatre. A partir de ces données, il va bâtir un système prédictif capable de classifier chaque anomalie candidate en s'appuyant sur l'ensemble des constituantes visibles de l'anomalie (c'est-à-dire ses axes, ses valeurs) mais aussi des constituantes cachées, ces dernières devant être ajoutées pour aider la machine à bâtir son modèle. Ces constituantes cachées peuvent être, par exemple, les imputations cumulées précédentes, des caractéristiques dérivées d'axes d'analyse (comme le responsable budgétaire, le pays, le fournisseur, le client livré / facturé, la devise, etc.).
{kind=link}
La sixième étape va utiliser pour la première fois le modèle sur un nouveau jeu de données, par exemple le mois de clôture suivant, afin de non plus proposer une liste simple d'anomalies candidates mais bien une liste classifiée par typologie d'erreur telle que définie en étape quatre. Il est important de préciser qu'à ce stade le modèle de classification est capable d'identifier des anomalies sur des combinaisons nouvelles et de proposer des solutions de résolution déjà établies et documentées.
{kind=link}
A la septième étape, qui est la dernière, le contrôleur analyse chacune des anomalies proposées par le système et peut le cas échéant : soit valider la proposition du système et basculer dans une phase de correction, soit rejeter la proposition du système. Dans ce cas de figure, le système peut s'être trompé de classification, alors le contrôleur modifiera le résultat de la machine et par conséquent, autorisera un ajustement du modèle.
Les deeptech, clés pour le Fast close ?
En s'appuyant sur des technologies issues de la deeptech telles que le Deep Learning et la RPA, il s'avère enfin réaliste de constituer des solutions d'automatisation partielle des processus de contrôle et de correction récurrents de la fonction Finance. Cette automatisation réduirait considérablement le temps de mise à disposition des données pertinentes à analyser par le contrôleur de gestion et permettrait d'accélérer la clôture.
Les sociétés ne s'y trompent pas, au vu de leurs investissements en matière d'IA.
" Investors are paying more attention to novel technologies that advance frontiers and address big needs and problems. Where's the deep tech money going? Seven fields feature the most active and promising technologies."(3)
{kind=link}
Figure3 - Investments per fields3
Pour en savoir plus
{kind=link}
Vladimir Lernould est directeur de missions au sein de l'entité Nell'Advisory de Nell'Armonia.
Fort de son expertise sur les outils décisionnels et de son appétence pour les Deeptech, il accompagne les directions financières dans l'amélioration et la modernisation de leurs systèmes d'information.
(1) BCG.2018.Intelligence Artificielle : seule une entreprise française sur cinq a pris la mesure de cette nouvelle révolution technologique. https://www.bcg.com/fr-fr/d/press/04december2018-france-press-release-208705
(2) Capgemini.2018. L'automatisation intelligente pourrait générer un gain de 512 milliards de dollars pour le secteur des services financiers d'ici 2020. https://www.capgemini.com/fr-fr/ressources/growth-in-the-machine/
(3) BCG.2019. A Deep Dive Into Deep Tech Investing. https://www.bcg.com/fr-fr/publications/2019/infographic-deep-dive-into-deep-tech-investing.aspx